Présentation de la notion de réplication sous SQL Serveur
Date de publication : 15/04/2010 , Date de mise à jour : 15/04/2010
Par
WOLO Laurent
Si vous envisagez de mettre en place la réplication ou souhaitez comprendre le fonctionnement de celui-ci, alors ce cours s'adresse à vous.
I. Objectifs
II. Présentation des données distribuées
III. Présentation de la réplication SQL Serveur
IV. Agents de réplication SQL Serveur
V. Types de réplication SQL Serveur SQL Serveur
V-A. Comment fonctionne la réplication de capture instantanée ?
V-B. Comment fonctionne la réplication transactionnelle
V-C. Comment fonctionne la réplication de fusion
VI. Modèles physiques de réplication
VI-A. Vue d'ensemble des modèles de réplication
VI-B. Modèle Éditeur/distributeur central, Plusieurs abonnés
VI-C. Modèle Abonné central/Éditeurs multiples
VI-D. Abonné/Editeur plusieurs abonnés
I. Objectifs
Ce cours vous permettra de comprendre les notions de réplication sous SQL Serveur depuis sa version 7.0
A la fin de ce cours, vous serez capable de :
- Décrire les objectifs visés par la réplication;
- Déterminer les types de réplication;
- Maîtriser les différents rôles des serveurs dans une réplication;
- Décrire les différents Modèles physiques ou topologie de la réplication;
II. Présentation des données distribuées
Les principaux objectifs qui conduisent à la mise en uvre de la réplication sont les besoins suivants :
- Rapprocher les données des utilisateurs finaux;
- L'indépendance des sites ;
- La séparation des serveurs OLTP à ceux traitant d'OLAP;
- La réduction des conflits de verrouillage
Il existe à cet effet, deux principales stratégies d'implémentations pour distribuer les données : celle qui utilise les moyens synchrones à savoir les serveurs distants, les serveurs liés et MS DTC et la deuxième technique qui utilise les moyens asynchrones,
la réplication qui est l'objet de notre cours.
La réplication : Elle duplique et distribue les copies récentes des données d'une base de données source sur une base de données de destination, généralement
sur un serveur distinct. Les sites autonomes sont pris en charge et peuvent être
en ligne par intermittence, permettant une plus grande évolutivité.
Les transactions distribuées : Elles garantissent que toutes les copies de vos données ont les mêmes valeurs au même moment. Chaque serveur inclus dans
une transaction distribuée doit être en ligne et doit pouvoir jouer le rôle qui lui a été attribué dans la transaction. Étant donné qu'un échec d'une transaction sur
un site affecte tous les sites, cette approche est moins évolutive que la réplication. N'optez pour cette approche que si les données doivent être synchronisées en permanence.
Pour implémenter l'une des solutions, vous devez tenir compte de trois principaux facteurs :
- La latence : Quelle est la durée minimale à laquelle les données doivent être synchronisées ?
- L'autonomie du site : Quel est le niveau d'autonomie de site autorisé ? Par exemple, lorsqu'une copie des données est disponible localement, quel est le délai admis avant de devoir se reconnecter au serveur central pour obtenir la copie actuelle ?
- La cohérence transactionnelle.
Voici un graphique qui vous donne une vue globale sur la technique à utiliser en fonction du couple latence/autonomie.
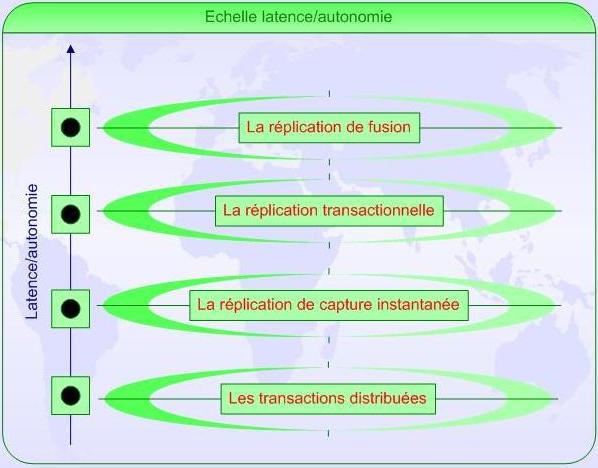
Echelle Autonomie/Latence
Les Transactions distribuées garantissent que tous les sites possèdent une même copies des données.
Mais elles impliquent une dépendance des sites très élevées.
Dans une réplication de capture instantanée, une copie des informations est remplacée par intervalles de temps, que les données soient modifiées ou non.
Dans une réplication transactionnelle, seules les données modifiées sont répliquées. La réplication a lieu au même moment que les mises à jour ce qui augmente la cohérence des transactions.
Ce type de transaction est une combinaison entre la réplication et les transactions distribuées.
Dans une réplication de fusion, plusieurs sites modifient les données, ces copies sont par la suite synchronisées.
III. Présentation de la réplication SQL Serveur
La réplication tire sa terminologie de l'entreprise d'édition. Nous allons définir les expressions à utiliser pour comprendre la mise en uvre de la réplication.
Il existe trois rôle de serveur dans le domaine de la réplication SQL Serveur :
- Un Editeur est un serveur qui contient les données à répliquer;
- Un Distributeur est un serveur qui stockent temporairement les données d'un ou plusieurs éditeurs avant de les distribuer aux abonnées;
- Un Abonné est un serveur qui reçoit les données d'un distributeur;
Les trois rôles peuvent être joués par des serveurs dédiés différents même si un seul serveur peut remplir les trois rôles à la fois.
Nous étudierons ces notions de modèles plus en détail dans le chapitre VI.
On retrouve également des termes suivants que nous allons définir :
- Une Publication est un ensemble d'un ou de plusieurs articles(tables individuelles, procédures stockées);
- Un Article est table unique ou un sous-ensemble des données d'une table, c'est une partie d'une publication;
- Un Abonnement est une requête portant sur la remise d'une copie d'une publication à un Abonné. L'abonnement définit la publication qui sera reçue, et où et quand elle sera reçue. Il existe deux types d'abonnements : par envoi de données (push) et par extraction de données (pull).
Il convient de souligner qu'on s'abonne à une publication donc à tous les articles de celle-ci
Même si la métaphore de l'édition est utile à la compréhension de la réplication, il est important de noter que la réplication SQL Server inclut des fonctionnalités qui ne sont pas représentées dans cette métaphore, en particulier la possibilité pour un Abonné d'effectuer des mises à jour et pour un serveur de publication d'envoyer des modifications incrémentielles aux articles d'une publication.
IV. Agents de réplication SQL Serveur
La réplication utilise une série de programmes indépendants, appelés Agents, pour effectuer les tâches associées au suivi des modifications et à la distribution des données. Par défaut, les Agents de réplication s'exécutent comme des travaux planifiés par SQL Server Agent qui doit être démarré pour que ces travaux puissent s'exécuter. Les Agents de réplication peuvent être également exécutés à partir de la ligne de commande et par des applications qui utilisent des objets de gestion de réplication (Réplication Management Objects, RMO). Les Agents de réplication peuvent être administrés à partir du moniteur de réplication SQL Server et de SQL Server Management Studio
 |
Je vous conseille vivement de configurer le service SQL Serveur Agent afin qu'il démarre sous un compte de domaine dont le mot de passe n'expire pas !
Ce compte doit avoir aussi reçu des privilèges sur les bases de données qu'il accède ! Nous verrons comment mettre cela en uvre dans les prochaines leçons.
|
L'Agent de capture instantanée est généralement utilisé avec tous les types de réplication. Il prépare le schéma et les fichiers de données initiaux des tables publiées et d'autres objets, stocke les fichiers de capture instantanée et enregistre les informations relatives à la synchronisation dans la base de données de distribution. L'Agent de capture instantanée s'exécute sur le serveur de distribution
L'Agent de lecture de journal est utilisé dans la réplication transactionnelle. Il déplace les transactions marquées pour la réplication depuis le journal des transactions du serveur de publication vers la base de données de distribution. Chaque base de données publiée à l'aide de la réplication transactionnelle possède son propre Agent de lecture du journal qui s'exécute sur le serveur de distribution et se connecte au serveur de publication (le serveur de distribution et le serveur de publication peuvent être installés sur le même ordinateur).
L'Agent de distribution est utilisé dans la réplication de capture instantanée et dans la réplication transactionnelle. Il applique la capture instantanée initiale sur l'Abonné et déplace les transactions conservées dans la base de données de distribution vers les Abonnés. L'Agent de distribution est exécuté sur le serveur de distribution pour les abonnements envoyés et sur l'Abonné pour les abonnements extraits.
L'Agent de fusion est utilisé dans la réplication de fusion. Il applique la capture instantanée initiale à l'Abonné et déplace puis rapproche les modifications de données incrémentielles effectuées. Chaque abonnement de fusion a son propre Agent de fusion qui se connecte à la fois au serveur de publication et à l'Abonné et les met à jour. L'Agent de fusion est généralement exécuté sur le serveur de distribution pour les abonnements envoyés et sur l'Abonné pour les abonnements extraits. Par défaut, il télécharge les modifications de l'Abonné vers le serveur de publication puis du serveur de publication vers l'Abonné.
L'Agent de lecture de la file d'attente est utilisé dans le cadre de la réplication transactionnelle avec l'option de mise à jour en attente. Il s'exécute sur le serveur de distribution et redéplace les modifications effectuées sur l'Abonné vers le serveur de publication. Contrairement aux Agents de distribution et de fusion, il n'existe qu'une seule instance de l'Agent de lecture de file d'attente pour servir l'ensemble des serveurs de publication et des publications pour une base de données de distribution donnée.
V. Types de réplication SQL Serveur SQL Serveur
V-A. Comment fonctionne la réplication de capture instantanée ?
Rappelons que dans une réplication de capture instantanée, une copie des informations est remplacée par intervalles de temps, que les données soient modifiées ou non
Elle est implémentée par l'agent de capture instantanée et l'agent de distribution.L'agent de distribution prépare les fichiers capturés contenant le schéma les objects de base de données et les données des tables publiées ,les stocke dans le dossier de capture qui, par défaut peut se situer sur un dossier partagé sur le distributeur et enregistre les tâches de synchronisation dans la base de distribution. Le dossier de capture instantanée être créé sur un emplacement alternative sur un autre serveur comme un lecteur réseau, un disque amovible ...
L'agent de distribution copie les données de la base de distribution vers les abonnées.
Dans ce type de réplication, l'agent de capture effectue les tâches suivantes:
- Etablir la connexion entre le distributeur et l'éditeur et place un verrou partagé sur toute les tables utilisées dans la publication, les données ne peuvent plus être modifier pendant la période de capture sur l'éditeur;
- Etablir une connexion entre l'éditeur et le distributeur et écrit une copie d'un schéma de table pour chaque article dans un fichier .sch et éventuellement des scriptes d'index dans un fichier .idx et des contraints dans .dri. D'autres objects de base de données comme les procédures stockées, les vues, les UDF ... peuvent également être publiés;
- Copier les données des tables publiées vers le dossier de capture instantanée;
- Enregistrer des lignes dans les tables MSrepl_commands et MSrepl_transactions de la base de distributions. Les enregistrements dans MSrepl_commands contient les emplacements des fichiers de synchronisation ainsi que les fichiers de scriptes .sch par exemple qui ont été créés pendant la phase 3 et les entrées dans MSrepl_transactions contient les tâches de synchronisation de l'abonné;
- La libération des verrous partagés posés en 1;
Chaque fois que l'agent de distribution s'exécute, il transfert les données vers l'abonnée. Il effectue les tâches ci-dessous :
- Etablir la connexion entre le serveur qui héberge le l'agent de distribution et le distributeur. Pour un abonnement envoyé, cet agent ce trouve sur le distributeur et pour un abonnement extrait, celui-ci se trouve sur l'abonné;
- Examiner les entrées des tables MSrepl_commands et MSrepl_transactions (de la base de distribution) à la lecture des emplacements des jeux de synchronisations ainsi que les commandes à appliquer sur l'abonné;
- Appliquer les schéma et les commandes à la base d'abonnement. Dans le cas ou la réplication est hétérogène, il effectue les corrections nécessaires et applique les articles à l'abonné;
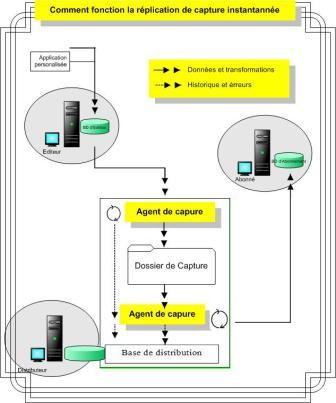
Fonctionnement de la transaction de capture instantanée
V-B. Comment fonctionne la réplication transactionnelle
Dans une réplication transactionnelle, les modifications incrémentielles apportées aux données sources sont appliquées à la destination avec une latence minimale.
Elle est implémentée par les agents de capture instantanées, de Lectoure du journal et de distribution.
Comme pour la réplication de capture instantanée, l'agent de capture prépare les fichier de capture, enregistrent les fichiers de capture dans le dossier de capture et inscrit les tâches de synchronisation dans la base de distribution. L'agent de lecture du journal surveille tous les journaux des bases de données configurés pour la réplication transactionnelle et copies toutes les transactions marquées pour la réplication du journal de transaction vers la base de données de distribution. Et enfin l'agent de distribution, vous l'avez certainement deviné, copie les données de la base de distribution vers les abonnées.
La réplication transactionnelle peut être utile dans un environnement où les abonnés doivent recevoir des modifications de données dès qu'elles ont lieu, avec une latence minimale rappelons le encore.
Avant de procéder à la réplication transactionnelle, l'Agent de capture instantanée doit effectuer une capture instantanée initiale. Vous pouvez spécifier la fréquence d'actualisation de cette capture.
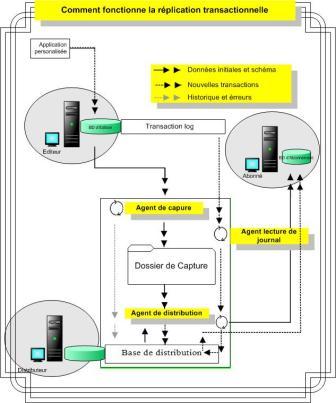
Fonctionnement de la transaction transactionnelle
V-C. Comment fonctionne la réplication de fusion
La réplication de fusion permet aux sites d'apporter des modifications
autonomes aux données répliquées. Les modifications de tous les sites sont
ensuite fusionnées soit périodiquement, soit sur demande. La réplication de
fusion n'assure pas la cohérence transactionnelle, mais garantit que tous les sites
convergent vers le même jeu de résultats.
La réplication de fusion peut être utile pour le filtrage ou le partitionnement des
données en fonction des pratiques en vigueur dans votre entreprise ; par
exemple, il est possible de structurer les données pour que les représentants
commerciaux puissent mettre à jour les enregistrements des clients qui
concernent leurs secteurs d'activité.
La réplication de fusion est implémentée par deux agents à savoir, l'agent de capture instantanée et l'agent de fusion.
Avant de commencer la réplication de fusion, l'Agent de capture instantanée
doit effectuer une capture instantanée initiale afin que l'abonné puisse avoir une base de données plus récente. Vous pouvez spécifier la
fréquence d'actualisation de cette capture. Dans le cas de la réplication de
fusion, l'Agent de capture instantanée copie certains fichiers ainsi que ceux
copiés dans les réplications de capture instantanée et transactionnelle. Il stocke
les modifications dans le dossier de travail de distribution.
 |
Le rôle du distributeur est très limitée, il est donc courant d'avoir le distributeur et l'éditeur sur la même machine.
|
Dans une réplication de fusion, le schéma de la base de données est modifiée:
- Une colonne rowguid de type uniqueidentifier est ajoutée dans chaque table publiée afin d'identifier chaque ligne de manière unique;
- SQL Serveur installe des déclencheurs sur chaque table publiée afin de tracker les changements;
- Et comme on l'a vu plus haut, l'agent de capture instantanée crée des procédures stockées personnalisées pour la mise à jour des données de l'abonné;
- SQL Serveur ajoute plusieurs tables systèmes pour l'audit des modifications des données, les synchronisations, la détection des conflits et le reporting;
Ce type de réplication permettant des mises à jour indépendantes, des conflits
peuvent survenir. Pour résoudre ces conflits, la réplication de fusion tient
compte de leur priorité.
- L'Agent de fusion analyse chaque ligne mise à jour.
L'historique des modifications apportées à une ligne s'appelle
l'enregistrement en ligne. Lorsque l'Agent de fusion fusionne les
modifications et rencontre une ligne pouvant contenir plusieurs
changements, il examine l'enregistrement en ligne pour déterminer
l'existence éventuelle d'un conflit. La détection des conflits a lieu au niveau
de la ligne ou de la colonne.
- L'Agent de fusion évalue les valeurs des données entrantes et en cours et
tout conflit entre les anciennes et les nouvelles valeurs est automatiquement
résolu en fonction des priorités affectées.
- Les valeurs des données ne sont répliquées sur d'autres sites que pendant la
phase de synchronisation qui se produit à quelques minutes, jours ou
semaines d'intervalle.
 |
Vous avez la possibilité de personnaliser les déclencheurs pour définir votre propre résolution des conflits.
|
Image pour illustrer le fonctionnement de la réplication de fusion :

Fonctionnement de la réplication de fusion
VI. Modèles physiques de réplication
VI-A. Vue d'ensemble des modèles de réplication
Les modèles physiques des réplications ne sont que les différentes répartitions des triplets des rôles (éditeur,distributeur,abonné) lors de la mise en place d'une réplication.
Les trois rôles peuvent très bien être tenus par un seul serveur physique. Rappelons que l'éditeur contient les données à répliquer, le distributeur stocke temporairement les données d'un ou de plusieurs éditeurs et enfin les abonnés sont les consommateurs de données.
Voyant donc les autres modèles physiques de réplication.
VI-B. Modèle Éditeur/distributeur central, Plusieurs abonnés
Le siège d'une entreprise veut envoyer les informations(Etat de stock, soldes des comptes client, catalogues des produits etc...) à ces agences.
VI-C. Modèle Abonné central/Éditeurs multiples
C'est le cas de plusieurs agences qui renvoient les mises à jours au siège.Le siège devient l'abonné de plusieurs agences qui sont des éditeurs.
VI-D. Abonné/Editeur plusieurs abonnés
Ici, les données sont d'abord répliquées vers un abonné qui à son tour va éditer et redistribuer ces données vers plusieurs autres abonnés. Ce modèle est très utilisé lors que l'on veut optimiser l'utilisation de la bande passante entre le premier éditeur et le second qui est abonné/éditeur/distributeurs.


Copyright © 2010 15/04/2010 Developpez LLC.
Tous droits réservés Developpez LLC. Aucune reproduction, même partielle, ne peut être faite
de ce site ni de l'ensemble de son contenu : textes, documents et images sans l'autorisation
expresse de Developpez LLC. Sinon vous encourez selon la loi jusqu'à trois ans
de prison et jusqu'à 300 000 € de dommages et intérêts.


